



电话
02088888888

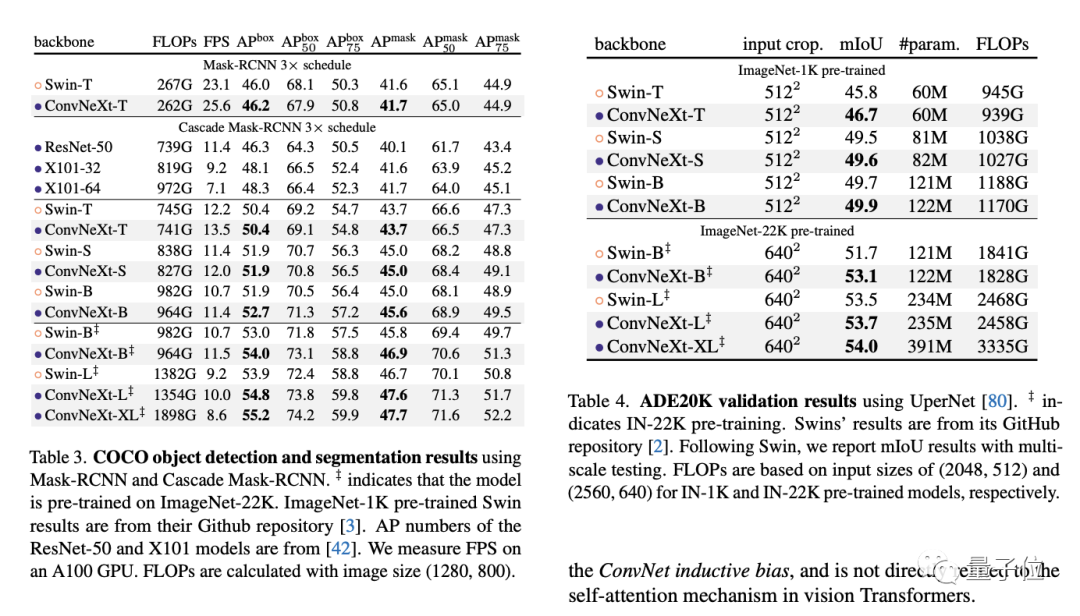
COCO和ADE20K数据集上,ConvNeXt模型在相同规模下实现了更优秀或相当水平的结果。LeCun表示,他对由Facebook与UC伯克利合作撰写的这篇论文深感关注,因为关于卷积模型与视觉Transformer之间的争议正在加剧。在GitHub上,ConvNeXt连续多天都排在趋势榜的第一位。有关这个学术问题,在国内引发了广泛关注,甚至一度成为知乎全站热榜上的热门话题。
在海外,有很多高校学者和谷歌、Arm等大型公司的工程师参与讨论,甚至碰到一些经典论文的作者 ——
ViT的创作者、EfficientNet系列的作者都前来展示他们的最新研究成果,希望进行一番比较。ViT 论文的第二篇作品补充了改进后的训练方法所得到的结果。而EfficientNet 系列的作者则补充了最新的v2 版本的结果。再说回LeCun,这次他真的不是来给自己的成果站台,而是提出了模型架构间相互借鉴是未来的方向。你以为我接下来要说“Conv是你需要的全部”了吗?不是!原来LeCun自己最喜欢的架构类似于DETR,首先是卷积层,随后结合了更多Transformer风格的层。虽然这次的ConvNeXt不是他所说的那种,但还是从Transformer身上学习了许多技巧,LeCun认为其中的成功之处就在于这一点。这篇论文的通讯作者谢赛宁也对这些讨论做出了回应。他说这篇论文并不旨在追求精度刷榜单,而更多的是试图探索卷积模型的设计空间。
的设计团队在过程中表现出了极大的克制,努力保持模型的简约。在我的观点里,我认为所有的模型架构都应该是友好的,只有过于复杂才是他们共同的敌人(如果你赞同奥卡姆剃刀原理的话)。{X}{N}{N}{X}{N}{X}究竟哪种架构才是最强的,不谈论这个问题,参与讨论的各位专家都对这篇论文有一个一致的感受:{X}{N}{N}{X}图表美观,结构清晰,实验充分,值得仔细阅读!
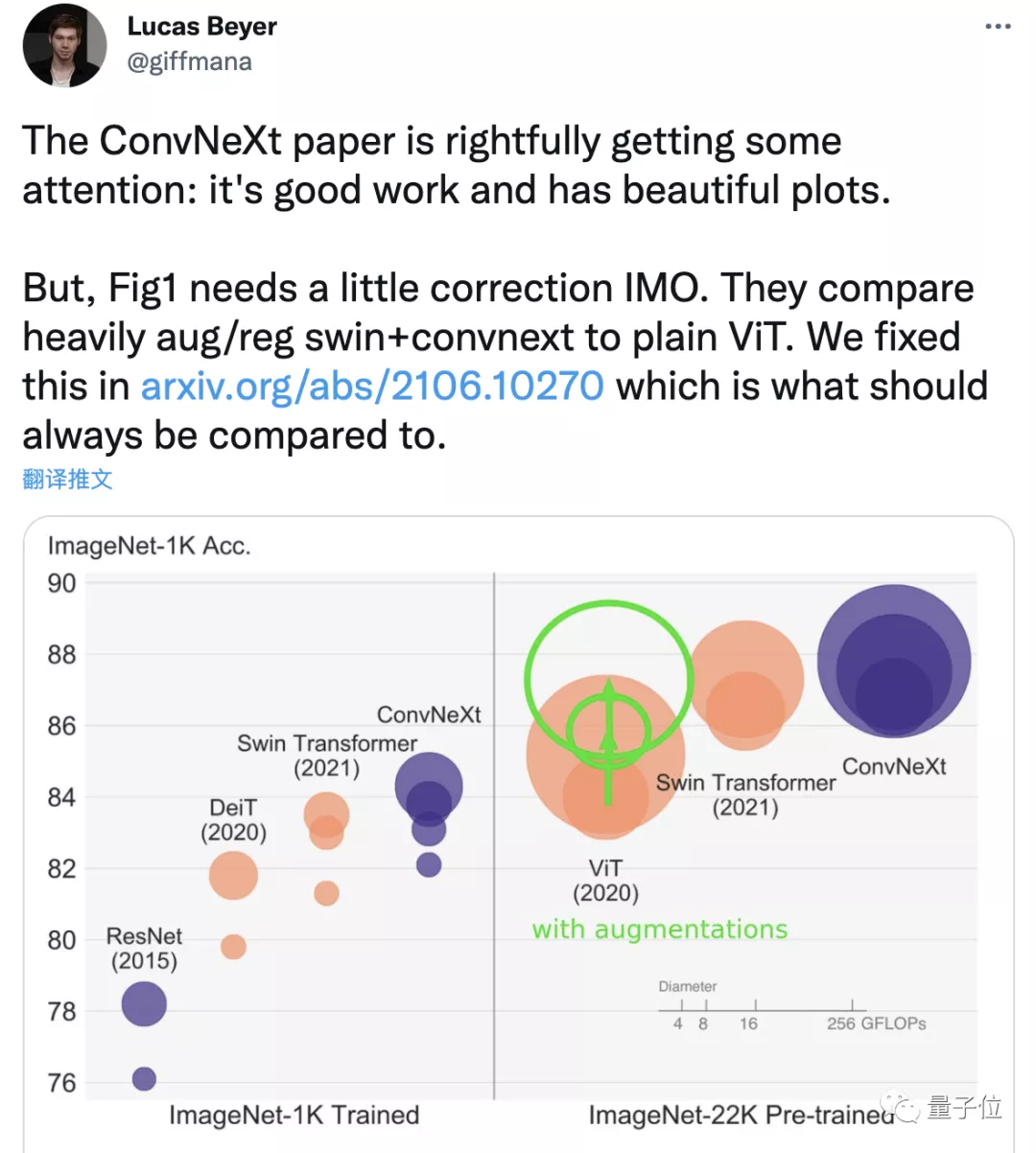
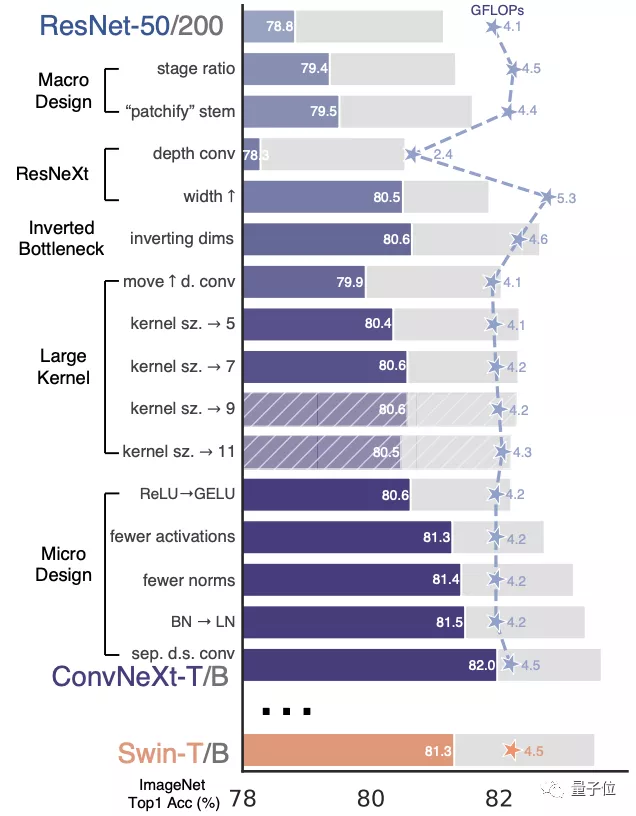
尤其是其中一幅精美的插图,可以说是全文的亮点,也是作者提供的“一目了然”的重要内容。
图片清晰展示了将ResNet-50的精度从78.8%提高到82.0%的详细步骤,以及使用的方法。
现在让我们首先来简要介绍一下本篇论文,以便了解ConvNeXt所采用的方法和背景信息。在之后再次审视架构之争时,我相信会有截然不同的观点。现在给CNN增添了Transformer的元素。先看一下摘要,其中有一句话关键地阐明了这篇论文的研究初衷。这篇文章旨在重新考虑卷积神经网络的设计可能性,采用现代方法对ResNet进行优化,并测试纯卷积模型的性能极限。

团队认为,尽管Transformer在视觉任务上取得了巨大成功,但全局注意力机制的复杂度与输入图像尺寸的平方成正比。以224×224和384×384分辨率来看,
对于ImageNet图像分类任务来说还算可以接受,但对于需要高分辨率图像的实际应用场景来说就不太理想。Swin Transformer通过重新引入卷积网络中的滑动窗口等多种特性来解决这个问题,但也使得Transformer变得更类似于CNN。Swin Transformer的成功让人们重新意识到卷积的重要性。根据这一点,本论文的研究思路是:如果让卷积模型也吸收Transformer架构中的各种方法,但不引入注意力模块,会产生怎样的效果?研究论文最终展现的内容是将标准ResNet逐步改进,使其更类似于Transformer的设计路线图。指的就是前面提到的备受赞誉的图片。在
条形图中,有色彩的区域表示Swint-T与ResNet-50在不同条件下的模型精度对比。
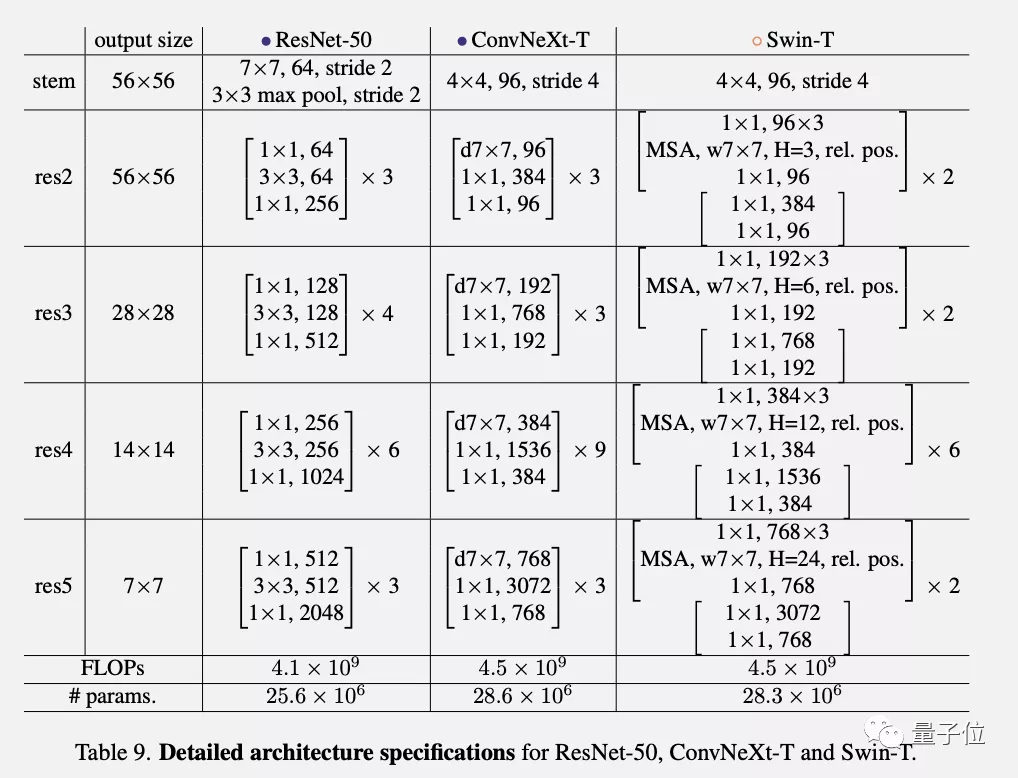
的灰色区域是对Swin-B和ResNet-200之间更大规模的比较,带阴影的部分表示该方法最终未被采用。为了公平对比,我们的模型在整个过程中的计算量与Swin Transformer 大致相当。研究团队总结了改动之处,分成了五个部分:宏观设计、引入ResNeXt、反转瓶颈层、增大卷积核、微观设计。但在详细解释每个部分之前,先介绍一下训练方法上的改进。
 0,视觉Transformer的训练方法不仅引入了新的模块和架构设计,还采用了与传统的CNN不同的训练方式。论文中所采用的训练方法类似于DeiT和Swin Transformer。将ResNet的epoch从90增加到300,并将优化器改用AdamW。在
0,视觉Transformer的训练方法不仅引入了新的模块和架构设计,还采用了与传统的CNN不同的训练方式。论文中所采用的训练方法类似于DeiT和Swin Transformer。将ResNet的epoch从90增加到300,并将优化器改用AdamW。在数据增强方面,引入了Mixup、Cutmix、RandAugment和Random Erasing技术。在正则化方面,采用了随机深度(Stochastic Depth)和标签平滑(Label Smoothing)的方法。经过这些措施,torchvision的ResNet-50性能提高了2.7个百分点,从76.1%增加到78.8%。

,这个结果显示,传统的卷积模型和视觉Transformer之间的性能差异在一定程度上也受到训练方法的影响。下面将详细介绍对模型本身进行的五项重大改动。
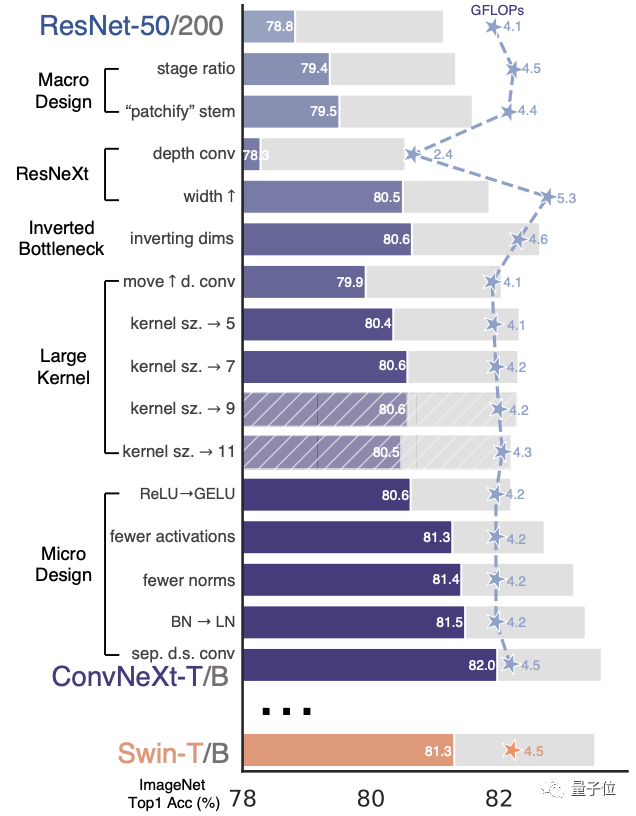
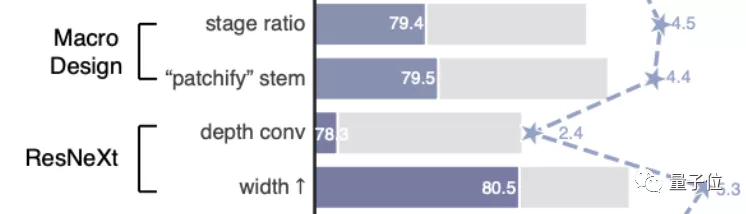
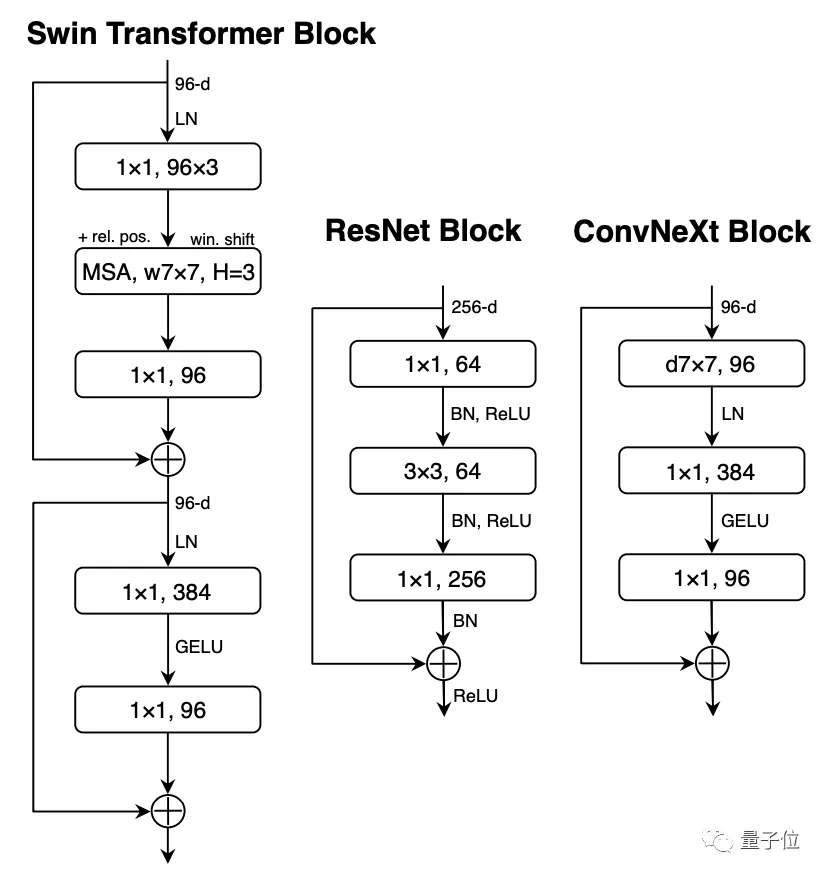
1、对整体结构 进行了两处调整,灵感源自Swin Transformer。首先要考虑的是block数量的比例分配,原始的ResNet-50有4个阶段,分别分配为(3, 4, 6, 3)。Swin Transformer吸取了多级阶段,每个阶段输出具有不同分辨率的设计理念,但比例已经调整为1:1:3:1。ConvNeXt遵循比例(3,3,9,3)进行分配,结果是模型准确率提高了0.6%,达到了79.4%。
进行了两处调整,灵感源自Swin Transformer。首先要考虑的是block数量的比例分配,原始的ResNet-50有4个阶段,分别分配为(3, 4, 6, 3)。Swin Transformer吸取了多级阶段,每个阶段输出具有不同分辨率的设计理念,但比例已经调整为1:1:3:1。ConvNeXt遵循比例(3,3,9,3)进行分配,结果是模型准确率提高了0.6%,达到了79.4%。
不过根据先前Facebook团队进行的两项研究,团队认为可能存在更合适的比例,需要进一步探索。这一部分的第二个变化是在词干层进行的修改。ResNet-50的传统做法是在输入图像上应用一个步长为2的7x7卷积,同时进行最大池化操作,这样就相当于将输入图像下采样了4倍。从ViT开始,它会首先将输入图像切成小块,针对每个小块进行非重叠的操作。Swin Transformer 的 patch 大小为 4x4,因此 ConvNeXt 也被设置为 4x4 非重叠卷积,步长为 4。这一变化让模型的准确度再次提高了0.1个百分点,目前达到了79.5%。
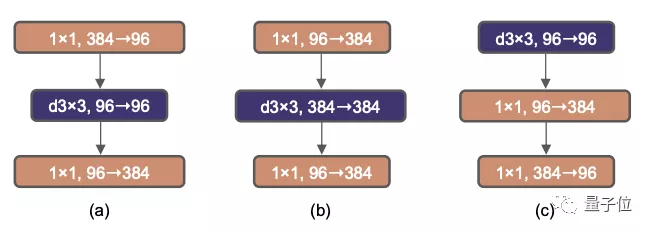
2、引入ResNeXt
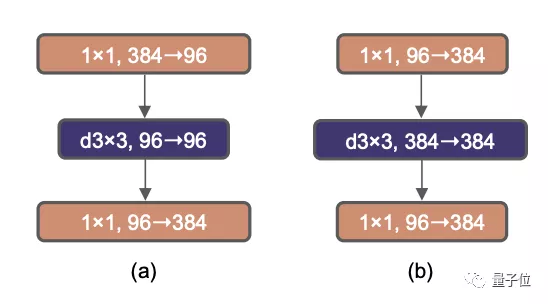
 ResNeXt是由本文的通讯作者谢赛宁在实习于Facebook何恺明团队时提出的一篇论文,发表在2017年的CVPR会议上。ResNeXt相对于原版的ResNet,在精度和计算量之间做出了更好的权衡,因此ConvNeXt计划继承这一优点。ResNeXt的主要概念是使用分组卷积,同时增加了网络宽度以补偿模型容量的损失。这一次的ConvNeXt让分组数直接与输入通道数相等,都设为96。每个卷积核在空间维度上处理一个通道,实现信息混合的作用,类似于自注意力机制的效果。这次调整使模型的准确度再提高了1%,达到了80.5%。MobileNetV2首次提出了反向瓶颈层这种方法
ResNeXt是由本文的通讯作者谢赛宁在实习于Facebook何恺明团队时提出的一篇论文,发表在2017年的CVPR会议上。ResNeXt相对于原版的ResNet,在精度和计算量之间做出了更好的权衡,因此ConvNeXt计划继承这一优点。ResNeXt的主要概念是使用分组卷积,同时增加了网络宽度以补偿模型容量的损失。这一次的ConvNeXt让分组数直接与输入通道数相等,都设为96。每个卷积核在空间维度上处理一个通道,实现信息混合的作用,类似于自注意力机制的效果。这次调整使模型的准确度再提高了1%,达到了80.5%。MobileNetV2首次提出了反向瓶颈层这种方法
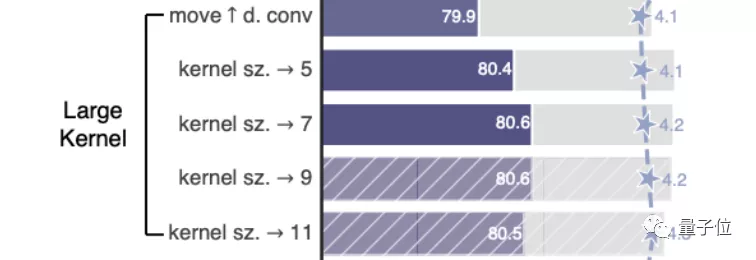
有趣的是,Transformer使用了类似的构造,因此ConvNeXt也进行了尝试。当进行这种反转时,虽然depthwise卷积层的FLOPs增加了,但在下采样残差块的作用下,整个网络的FLOPs反而减少。模型的精度也略微提升了0.1%,达到了80.6%。在基于ResNet-200的更大型号中,改进表现更为显著,准确率从81.9%提高至82.6%。4、从VGG开始,增加卷积核的尺寸,3x3卷积核成为了标准选择,并且小型卷积核也在硬件中得到了广泛适配。Swin Transformer采用了类似卷积核的局部窗口机制,但其大小至少为7x7。基于这一事实,ConvNeXt计划重新探索不同卷积核尺寸的效果。在反转瓶颈层之后增加卷积层的维度会使参数数量显著增加,因此直接增大卷积核可能会造成问题。在进行此操作之前,有一个额外的步骤,需要在瓶颈层反转的基础上,将depthwise卷积层提前到b到c之间。
这个步骤导致模型精度暂时降低到了79.9%。在对
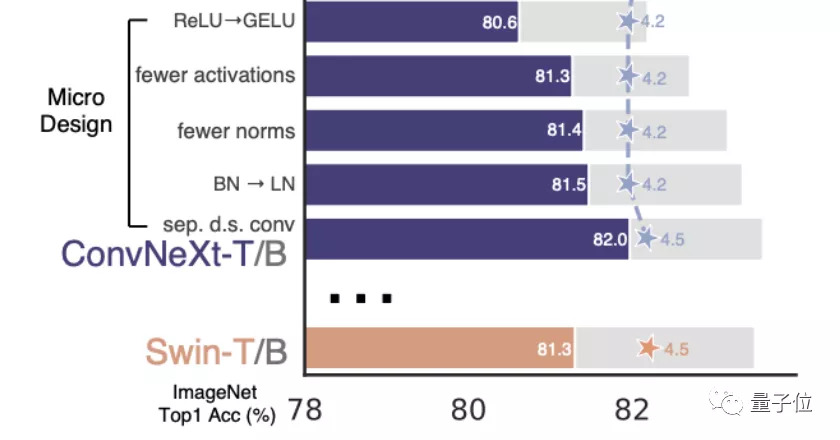
进行试验后,尝试了不同的卷积核大小,从3x3到11x11都有涉及。在使用7x7的卷积核时,模型的准确度重回80.6%。在ResNet-200上增加效果不太明显,因此最后卷积核的大小设置为7x7。5、层级之上的微观设计是接下来的重点,主要关注于激活函数和归一化。在激活函数中,卷积模型通常使用简单又高效的ReLU。GELU比ReLU更平滑,并被BERT、GPT-3以及ViT等NLP模型采纳。在ConvNeXt的研究中,采用GELU并未为模型的精度带来提升,但也可以作为一种可行方案。每个Transformer块中的MLP块只有一个激活函数。CNN的普遍做法是在每个卷积层之后都添加一个激活函数
。ConvNeXt尝试遵循与Transformer相同的做法,只保留了两个1x1层之间的GELU激活函数。该方法让模型的精度提高了0.7%,最终达到了81.3%,与Swin-T模型处于同一水平。归一化层的数量也减少了,精度再次提高了0.1%,达到了81.4%,超过了Swin-T。
接下来的步骤是将LN(层归一化)替换BN(批次归一化),这在原始版本的ResNet中会导致精度下降。 在进行了以上各种修改的基础上,ConvNeXt模型的这个操作使精度提高了0.1%,目前达到了81.5%。最后一阶段是将下采样层分离。在ResNet中,降采样是由残差块来实现的,而Swin Transformer则采用了单独的降采样层。ConvNeXt尝试了相似的方法,通过使用2x2的卷积核和步长为2来进行下采样。 的结果却导致了训练的不稳定。在后来,他们找到了解决方法,在每个下采样层之前、主干之前和最后的全局平均池化之前都添加层归一化。所有对
的结果却导致了训练的不稳定。在后来,他们找到了解决方法,在每个下采样层之前、主干之前和最后的全局平均池化之前都添加层归一化。所有对以上的修改终于合并在一起,ConvNeXt单个块的结构最终确定下来。最终得出的ConvNeXt-T小型模型,精确度达到了82.0%,比Swin-T的81.3%要高。ConvNeXt在比较更大的模型时稍微领先,但优势变小了。
有趣的是,团队总结说:
在所有这些方法中,这篇论文并非独创,它们都可以在过去十年的多项研究中找到。ConvNeXt是将这些方法集中研究后发现,在ImageNet-1k上能够超越Transformer的纯卷积模型。每种规模的ConvNeXt在FLOPs、参数量、吞吐量和内存使用量方面都与Swin Transformer大致相当。ConvNeXt的优势还在于,它不需要引入额外的移动窗口注意力或相对位置偏置等特殊结构。
的简洁性保持,也就意味着更易于部署。最终,团队希望通过这篇论文,挑战一些已经被普遍接受和默认的观点。为了激励研究者重新思考卷积在计算机视觉中的重要性,也是我们的目标之一。ConvNeXt引发了有关视觉模型架构的激烈争论,学术界和工业界更多人提出了不同的观点。马毅教授表示,他不太赞同这种表面上的架构之争。结合他的下一条微博,马毅教授希望大家能够进一步关注理论基础。在知乎上有一位匿名用户提出,这篇文章对工业界更有价值。在之前,Transformer的表现尽管很好,但在实际应用中很难部署。大家一直都期待着看到卷积方法的最终效果。这恰恰是ConvNeXt研究的初衷。从研究团队对谢赛宁在论文中对另一讨论的回应中可以得出结论,他们认为ImageNet的结果并不是关键问题。他们更想要强调和引起大家的关注的是卷积模型在目标检测等后续任务中的性能表现。ConvNeXt在COCO和ADE20K数据集上进行了验证,对于后续任务表现相当好,甚至比SwinTransformer更好。
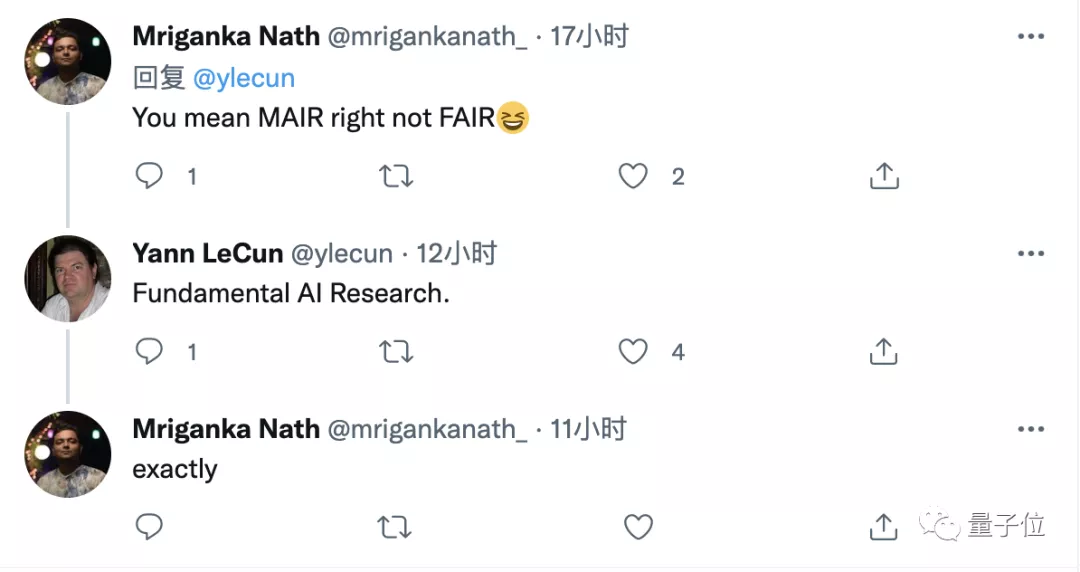
随后的讨论中还发生了一件有趣的事情。LeCun先生,有人问您,您的部门应该随公司改名为Meta,为什么在论文上还使用FAIR的署名?LeCun开了一个小玩笑,表示这代表人工智能基础研究。也相当风趣~。作者团队前面提到的谢赛宁是FAIR研究员,他本科毕业于上海交通大学ACM班,博士毕业于UC圣地亚哥分校。谢赛宁在攻读博士期间曾在FAIR实习,期间与何恺明合作完成了ResNeXt,并担任了该论文的第一作者。
不久前备受关注的何恺明发表了一篇与MAE有关的论文,他也参与了其中。
本文中的通讯作者是ConvNeXt(假名),令人意外的是,本文的第一作者也是在博士阶段来实习的。
的名字是刘壮,他在美国加州大学伯克利分校攻读博士学位,并且是清华大学姚班的毕业生。DenseNet的作者曾荣获2017年CVPR最佳论文奖。
论文链接 https://arxiv.org/abs/2201.03545
Github链接: https://github.com/facebookresearch/ConvNeXt








邮箱:youweb@qq.com
Q Q:http://wpa.qq.com/msgrd?v=3&uin=88888888&site=qq&menu=yes


加微信咨询